株式会社キャンサースキャンのプレスリリース
キャンサースキャンのデータサイエンス本部に所属し京都大学研究員でもある藤岡裕平および三澤大太郎と京都大学の福間真悟 特定教授および滋賀大学の池之上辰義 講師との共著論文「In Medical Claims Data, Enhancing Predictive Performance for Major Adverse Cardiovascular Events Using Cross Attention*1」が、機械学習分野のトップカンファレンス KDD 2024*2の Workshop「Artificial Intelligence and Data Science for Healthcare: Bridging Data-Centric AI and People-Centric Healthcare」に採択されました。2024 年 8 月 26 日に開催された KDD 2024 で、本論文の内容を発表いたしました。
研究背景
レセプトデータ (医療費の請求に関するデータ) は、患者の診断や治療に関する臨床情報と費用や請求情報などの財務情報を含んでいます。最近、医学研究でこれらのデータから大規模なデータベースを構築し、疾患予測に活用することが期待されています。しかし、これらのデータ内の臨床情報は医学的に構造化されておらず、分析への応用には制限があります。
研究概要
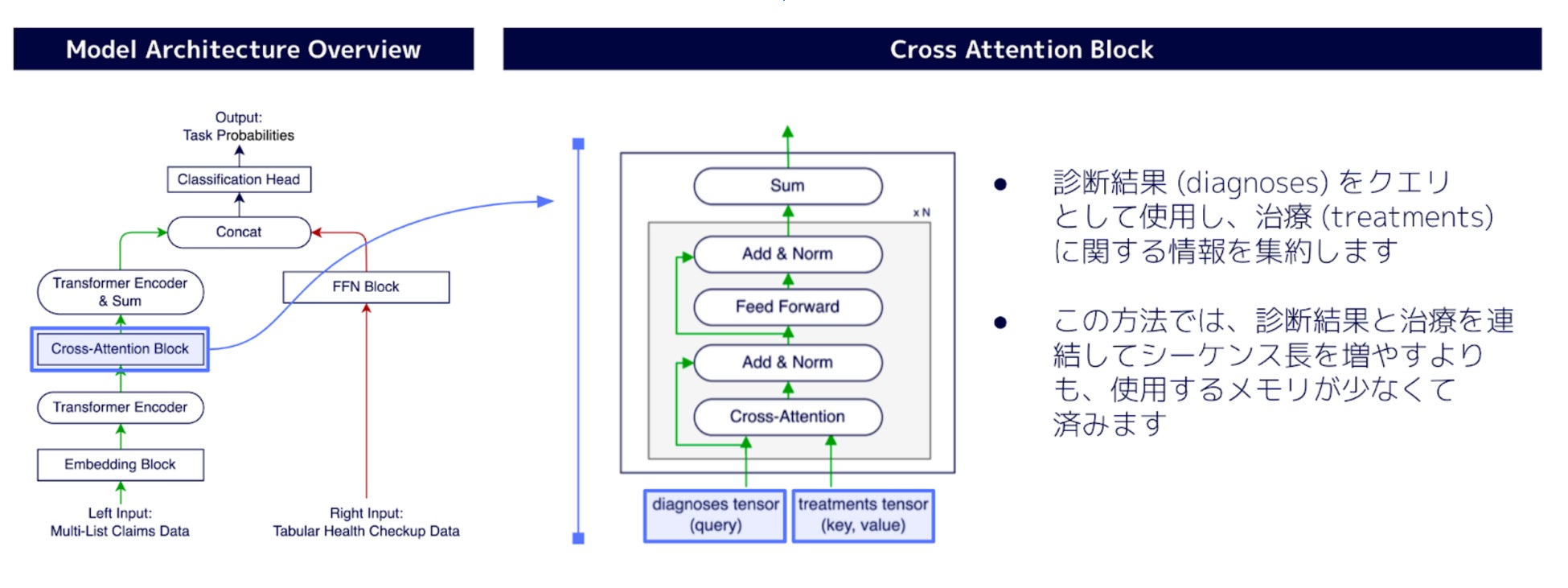
全国規模の保険者のレセプトデータ (2014 年 4 月 ~ 2022 年 3 月診療分) を利用し、主要心血管疾患(MACE)の予測モデルの性能を向上させることを目的としました。心筋梗塞や脳血管疾患、心不全、末梢動脈疾患などの複合疾患であるMACEは世界的に主要な死因であり、予防は喫緊の課題です。私たちは、診断と治療の関係を効果的に重み付けして予測に活用するために、Cross Attention メカニズムを応用しました。具体的には、レセプトデータに含まれる診断と治療の月次データを Transformer Encoder を用いて変換し、その後 Cross Attention を用いて診断と治療の相互関係を反映した特徴ベクトルを作成しました。これと健康診断の検査値データを統合し、MACEを予測する新たな予測モデル*3を構築しました。
研究結果
提案した Cross Attention に基づくモデルは、ROC-AUCスコアが0.7720と、従来の心血管疾患予測モデル、LGBM、Self Attention に基づくモデルなどのベンチマークモデルよりも高い精度を示しました。これらの結果は、Cross Attention をレセプトデータに活用することで、予測モデルのパフォーマンスが向上することを示しています。この研究は、公衆衛生サービスの対象者候補となる心血管ハイリスク者を精度良く抽出することで、我が国の健康増進サービス向上に寄与する可能性があり、将来的には他の疾患予測にも応用できる Pre-Trained Model の開発を目指しています。
*1 https://openreview.net/pdf?id=V0GnWj14sl
*3-a Cross Attention を応用した提案モデル
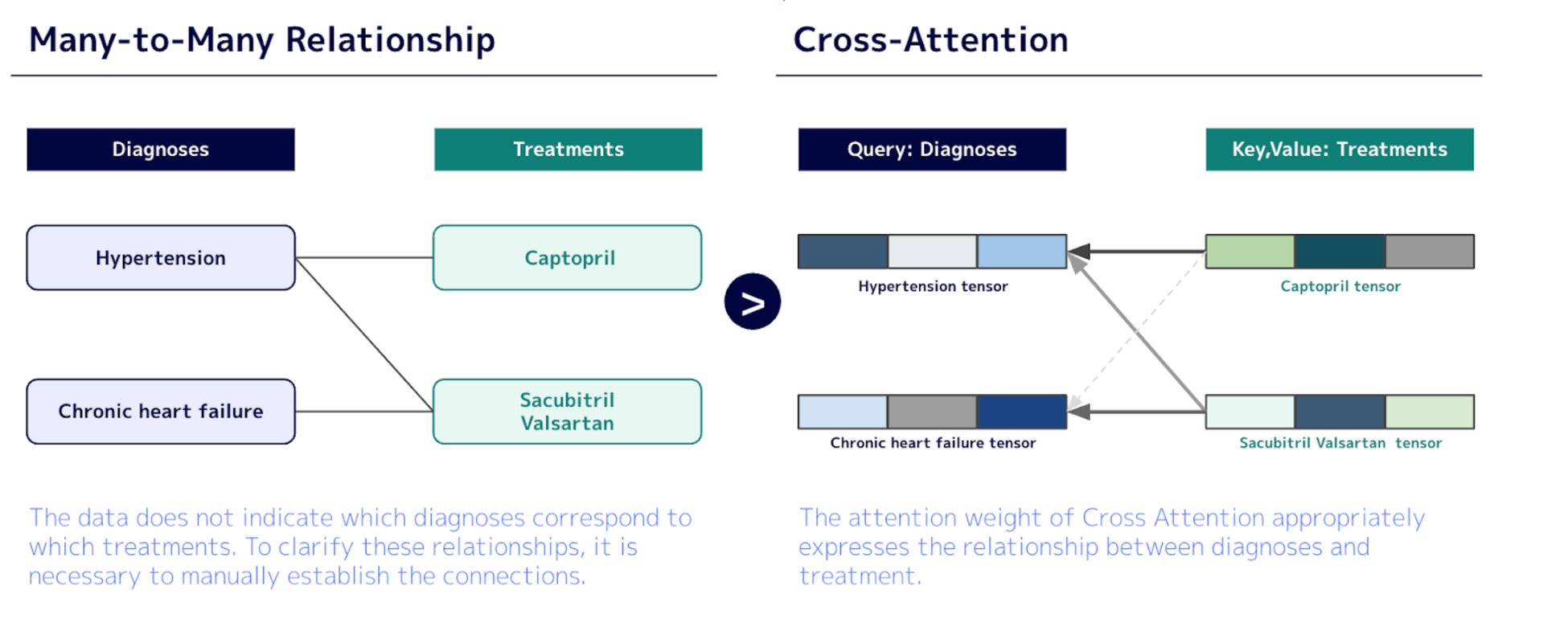
*3-b Cross Attention を応用することで捉えられる診断と治療の多対多の関係
この件に関するお問い合わせ先
株式会社キャンサースキャン
広報担当
TEL:03-6420-3390
E-mail:info@cancerscan.jp